一個(gè)網(wǎng)站想要在搜索引擎獲得好的排名,就要從搜索引擎獲取流量。在國內能夠帶來(lái)流量的,僅僅有百度,360,搜狗。而在國外能夠帶來(lái)流量的有谷歌,MSN,yahoo(雅虎),bing等幾種。這些搜索引擎帶來(lái)流量的原理大同小異,都是循著(zhù)鏈接抓取,放出爬蟲(chóng)(即程序,也可稱(chēng)為蜘蛛)。
搜索引擎蜘蛛是一邊抓取一邊爬行,把爬取到的代碼存入自己的索引鏈接庫中進(jìn)行篩選,如果是它覺(jué)得需要的內容它才會(huì )展現出來(lái)(即被蜘蛛(spider)所爬取收錄的網(wǎng)頁(yè))。我們就能夠在搜索引擎上面搜索到我們的網(wǎng)站。
幾種常見(jiàn)的搜索引擎爬蟲(chóng)的名稱(chēng):
360爬蟲(chóng)名稱(chēng)名稱(chēng):360Spider
百度(Baidu)爬蟲(chóng)名稱(chēng):Baiduspider
雅虎(Yahoo)爬蟲(chóng)名稱(chēng):Yahoo! Slurp
谷歌(Google)爬蟲(chóng)名稱(chēng):Googlebot
搜狗(sogou)蜘蛛名稱(chēng):Sogou spider
MSN的蜘蛛名稱(chēng):msmbot
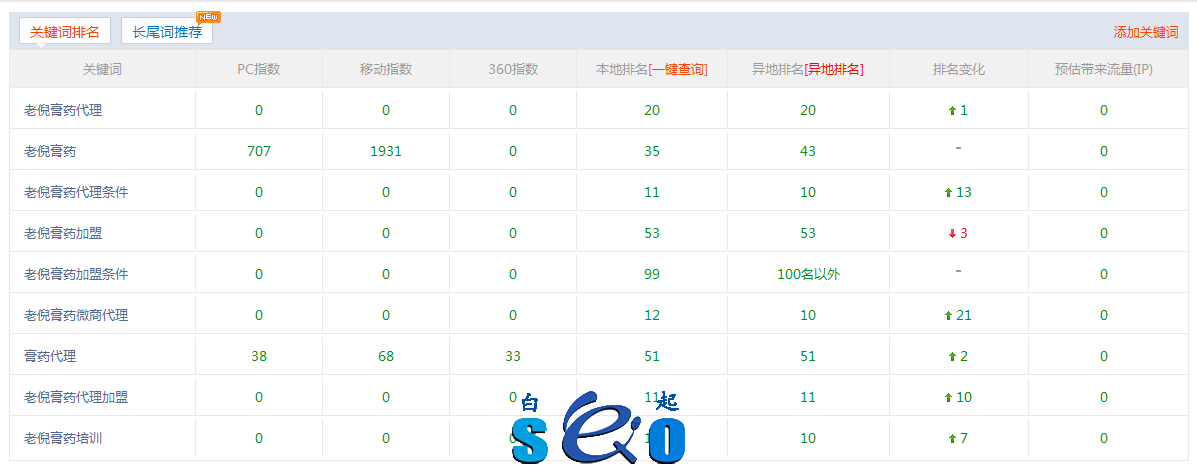
網(wǎng)站SEO優(yōu)化第一步要做到的就是吸引蜘蛛來(lái)爬取我們的網(wǎng)站,搜索引擎的蜘蛛爬取到我們的網(wǎng)站,都會(huì )有痕跡,都會(huì )有自己的代理名稱(chēng),各位站長(cháng)都可以在IIS日志文件中分辨出分別是哪個(gè)搜索引擎的蜘蛛。
比較常見(jiàn)的搜索引擎蜘蛛有:
Baiduspider+(+baidu/search/spider.htm:baidu/search/spider.htm)
代表百度蜘蛛爬取過(guò)的痕跡
Mozilla/5.0 (compatible; Yahoo! Slurp China; http://misc.yahoo.com.cn/help.html)
雅虎中國蜘蛛爬取過(guò)的痕跡
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Google蜘蛛爬取過(guò)的痕跡
Sogou+web+robot+(+http://www.sogou.com/docs/help/webmasters.htm#07)
搜狗蜘蛛爬取過(guò)的痕跡
Sosospider+(+http://help.soso.com/webspider.htm)
搜搜蜘蛛爬取過(guò)的痕跡
Mozilla/5.0 (compatible; YodaoBot/1.0; http://www.yodao.com/help/webmaster/spider/; )
有道蜘蛛爬取過(guò)的痕跡
因為蜘蛛不能夠爬取互聯(lián)網(wǎng)所有的網(wǎng)站,實(shí)際上最大的搜索引擎也只是爬取了收錄了互聯(lián)網(wǎng)很小的一部分。如果SEO優(yōu)化人員想要自己的網(wǎng)站更多的被搜索引擎收錄,那么必須得設法把蜘蛛吸引過(guò)來(lái)抓取。搜索引擎一般都會(huì )爬取比較重要的頁(yè)面。
蜘蛛爬取重要頁(yè)面需要滿(mǎn)足幾個(gè)條件:
1、網(wǎng)站權重問(wèn)題,權重越高的網(wǎng)站蜘蛛會(huì )爬取的更加深入,幾乎每個(gè)頁(yè)面都會(huì )爬取到,就會(huì )有更多的內頁(yè)被收錄。
2、網(wǎng)站的更新頻率,蜘蛛會(huì )把每次爬取的網(wǎng)站存儲起來(lái),方便第二次爬取,如果第二次爬取到你優(yōu)化的網(wǎng)站,發(fā)現頁(yè)面有更新,蜘蛛就會(huì )爬取到你的新內容,如果之后每天更新,那么蜘蛛也會(huì )養成習慣,每天定時(shí)來(lái)爬取你的網(wǎng)站。
3、網(wǎng)站內容質(zhì)量,質(zhì)量高、可讀性比較強的頁(yè)面,搜索引擎抓取到就更容易收錄,從而收錄之后,給我們的頁(yè)面權重也會(huì )有提高。下次也會(huì )繼續來(lái)爬取我們的網(wǎng)站,因為搜索引擎就喜歡有價(jià)值的頁(yè)面,可讀性強的頁(yè)面,語(yǔ)句符合邏輯的頁(yè)面。
4、導入鏈接,這種分為外部鏈接和內部鏈接,如果要蜘蛛來(lái)抓取一個(gè)頁(yè)面,那么這個(gè)頁(yè)面必須要有導入鏈接,要不然蜘蛛根本就不能夠知道這個(gè)頁(yè)面的存在,那么高質(zhì)量的導入鏈接,可以很好的引導蜘蛛抓取我們頁(yè)面?! ?/span>
5、頁(yè)面在首頁(yè)有鏈接,一般來(lái)說(shuō)我們在自己網(wǎng)站更新,更新的鏈接最好是要出現在首頁(yè),因為首頁(yè)是權重最高的,蜘蛛訪(fǎng)問(wèn)最多,最頻繁的也是我們的首頁(yè),如果首頁(yè)有更新的鏈接,可以讓蜘蛛更快更好的爬取到我們更新的頁(yè)面,從而更好的收錄我們的頁(yè)面。
在日志的文件發(fā)現蜘蛛,但是頁(yè)面沒(méi)有被收錄?
1、重復度很高的內容,蜘蛛在抓取你網(wǎng)站的時(shí)候,發(fā)現你的網(wǎng)站存在之前被抓取過(guò)的內容太過(guò)相似,會(huì )認為你的網(wǎng)站是抄襲或者復制別人的內容,很有可能就不會(huì )繼續爬取你的網(wǎng)站了,從而造成蜘蛛來(lái)過(guò),卻不收錄你的頁(yè)面。
2、不能識別的圖片,視頻,flash,js, frame框架,ajax。
3、已經(jīng)收錄了,但是沒(méi)人點(diǎn)擊,或者只是看了一眼就走,即使收錄了以后也會(huì )撤掉。
圖片會(huì )被抓取嗎?
答:會(huì )。 圖片蜘蛛,專(zhuān)門(mén)抓圖片,圖片也會(huì )帶來(lái)流量,但是圖片沒(méi)有規定尺寸。
圖片蜘蛛是怎么抓取圖片的?
1、整站,網(wǎng)站品牌詞。
2、Alt屬性。Alt屬性查看,單機右鍵,打開(kāi)審查元素(代碼里面寫(xiě)著(zhù):xxx效果圖),或查看源代碼。
3、圖片周?chē)奈淖置枋觥?/span>
注意: 第1和第3通常不做,因為圖片蜘蛛識別的幾率低,而第2種是能完全識別的,因為Alt是圖片屬性標簽。
深圳網(wǎng)站建設-免費網(wǎng)站優(yōu)化分析!
 網(wǎng)站建設_QQ咨詢(xún):307739391
網(wǎng)站建設_QQ咨詢(xún):307739391  網(wǎng)站優(yōu)化_電話(huà):15907554344
網(wǎng)站優(yōu)化_電話(huà):15907554344 網(wǎng)站建設咨詢(xún)
網(wǎng)站建設咨詢(xún)


